Retrieval augmented generation
What is retrieval augmented generation (RAG)?
Large language models (LLM) have been the biggest star in generative AI, however their applications to a specific domain needs some adaption from the pretrained weights. There are two main ways to do so: 1. finetuning, which is to directly train the model on top of specific datasets, such that the model weights contain new information about the new domain. 2. RAG, which is to retrieve external domain knowledge during generation, much like an “open book” exam where the model can gain access to more accurate external information. The original Rag paper was published in 2020, it used DPR as retriever and BART as the LLM for generation. With the rapid development of LLMs, RAG technique can be adapted to bigger and better models such as LLama and GPT, however the underlying principle remains the same. In this post, I will analyze HuggingFace’s original RAG implementation and address some technical questions that are difficult to find answers to online.
HuggingFace implementation of RAG
RAG is part of HuggingFace’s transformers library. As it belongs to such a big library requiring a multitude of functionalities and abstractions, its source code is a mess and it is not easy to pinpoint the key lines of code within. However, roughly the RAG model implementation can be found and studied here, whereas ways to use it can be found here (training generator) and here (training both retriever and generator). At a high level, RAG consists of two main components: a retriever and a generator, working together to formulate an answer to a prompt. The retriever’s job is to find relevant documents within some indexed documents based on the prompt. It can use traditional techniques such as BM25 or more modern, embedding-based techniques such as DPR (Dense Passage Retrieval) or ANCE (Approximate Nearest Neighbor Negative Contrastive Estimation). The generator then integrates these documents with the original prompt to create a new, enriched prompt, which it uses to generate the final answer. Mathematically, there are 2 ways to implement the above idea:
-
RAG-sequence model, where we first retrieve the $k$ most relevant documents according to the initial prompt, and then use them during our generation by marginalizing over their relevance to the initial prompt:
\[\begin{aligned} p_{sequence}(y|x) \approx \sum_{z \in \text{top-}k(p(.|x))} p_\eta(z|x) \prod_i^N p_\theta(y_i|x, z, y_{1:i-1}) \end{aligned}\]where $x$ is the initial prompt, $y$ is the generated output, $z$ are the $k$ retrieved documents according to their relevance scores, $\eta$ and $\theta$ are the retriever and generator parameters respectively.
-
RAG-token model, where we retrieve the $k$ most relevant documents and marginalize over their relevance each time we want to generate a new token according to the evolving prompt containing previous generations:
\[\begin{aligned} p_{token}(y|x_i) \approx \prod_i^N \sum_{z \in \text{top-}k(p(.|x_i))} p_\eta(z|x_i) p_\theta(y_i|x_i, z, y_{1:i-1}) \end{aligned}\]where $x_i$ is the initial prompt appended by the ith generated token, $y$ is the generated output, $z$ are the $k$ retrieved documents according to their relevance scores, $\eta$ and $\theta$ are the retriever and generator parameters respectively.
How is RAG implemented in HuggingFace?
The HuggingFace implementation of RAG can be shown in the UML diagram below, where I colored the core classes in blue:
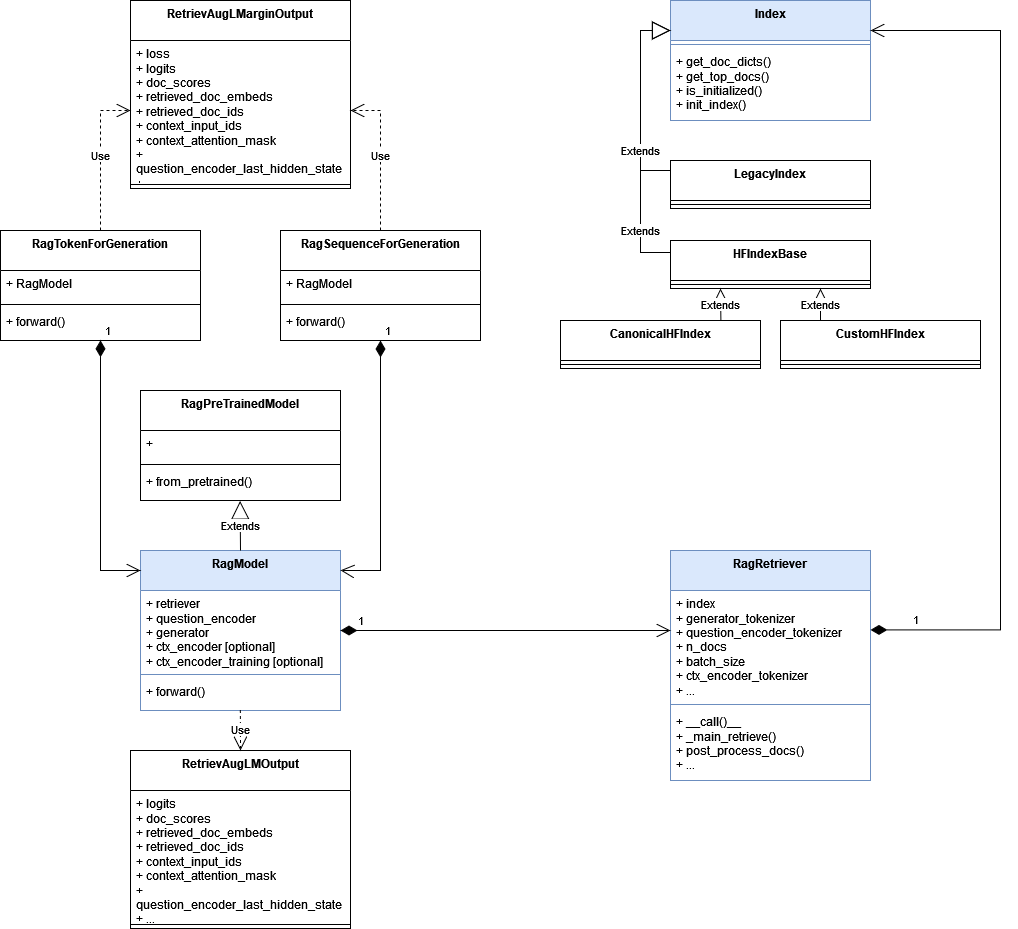
The RagModel class is the main class where most of the magic happens. Internally, it uses a LLM generator and a RagRetriever, and can be accessed via one of the 2 APIs associated with the 2 models above, RagSequenceForGeneration and RagTokenForGeneration. Taking the sequence generation pipeline as an example, the generation pipeline can be established with the following codes:
from transformers import AutoTokenizer, RagRetriever, RagSequenceForGeneration
import torch
tokenizer = AutoTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained(
"facebook/rag-sequence-nq", index_name="exact", use_dummy_dataset=True
)
# initialize with RagRetriever to do everything in one forward call
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
inputs = tokenizer("How many people live in Paris?", return_tensors="pt")
targets = tokenizer(text_target="In Paris, there are 10 million people.", return_tensors="pt")
input_ids = inputs["input_ids"]
labels = targets["input_ids"]
outputs = model(input_ids=input_ids, labels=labels)Internally, RagSequenceForGeneration utilises a RagModel class with the following structure, I skipped the less important codes and added some comments:
class RagModel(RagPretrainedModel):
def __init__(
self,
config: Optional[PretrainedConfig] = None,
question_encoder: Optional[PreTrainedModel] = None,
generator: Optional[PreTrainedModel] = None,
retriever: Optional[RagRetriever] = None,
**kwargs,
):
...
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
decoder_input_ids: Optional[torch.LongTensor] = None,
decoder_attention_mask: Optional[torch.BoolTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
doc_scores: Optional[torch.FloatTensor] = None,
context_input_ids: Optional[torch.LongTensor] = None,
context_attention_mask: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_retrieved: Optional[bool] = None,
n_docs: Optional[int] = None,
) -> Union[Tuple[torch.Tensor], RetrievAugLMOutput]:
...
# First, we need to encode the question in order to retrieve relevant documents via the retriever
question_enc_outputs = self.question_encoder(
input_ids, attention_mask=attention_mask, return_dict=True
)
question_encoder_last_hidden_state = question_enc_outputs[0] # hidden states of question encoder
...
# Second, we get the most relevant documents from the retriever and use their relevance as prior
# We train both the retriever and the generator
if self.context_encoder_training:
(
context_input_ids,
context_attention_mask,
retrieved_doc_embeds,
retrived_doc_input_ids,
retrived_doc_attention_mask,
retrieved_doc_ids,
) = (
retriever_outputs["context_input_ids"],
retriever_outputs["context_attention_mask"],
retriever_outputs["retrieved_doc_embeds"],
retriever_outputs["tokenized_doc_ids"],
retriever_outputs["tokenized_doc_attention_mask"],
retriever_outputs["doc_ids"],
)
context_input_ids = context_input_ids.to(input_ids)
context_attention_mask = context_attention_mask.to(input_ids)
retrived_doc_input_ids = retrived_doc_input_ids.to(input_ids)
retrived_doc_attention_mask = retrived_doc_attention_mask.to(input_ids)
retrieved_doc_embeds = self.ctx_encoder(
retrived_doc_input_ids, attention_mask=retrived_doc_attention_mask, return_dict=True
).pooler_output
retrieved_doc_embeds = retrieved_doc_embeds.view(
-1, n_docs, question_encoder_last_hidden_state.shape[1]
) # reshaping
# compute doc_scores involving ctx_encoder
doc_scores = torch.bmm(
question_encoder_last_hidden_state.unsqueeze(1), retrieved_doc_embeds.transpose(1, 2)
).squeeze(1)
# We train the generator only
else:
context_input_ids, context_attention_mask, retrieved_doc_embeds, retrieved_doc_ids = (
retriever_outputs["context_input_ids"],
retriever_outputs["context_attention_mask"],
retriever_outputs["retrieved_doc_embeds"],
retriever_outputs["doc_ids"],
)
# set to correct device
retrieved_doc_embeds = retrieved_doc_embeds.to(question_encoder_last_hidden_state)
context_input_ids = context_input_ids.to(input_ids)
context_attention_mask = context_attention_mask.to(input_ids)
# compute doc_scores
doc_scores = torch.bmm(
question_encoder_last_hidden_state.unsqueeze(1), retrieved_doc_embeds.transpose(1, 2)
).squeeze(1)
...
# Third, we generate involving results from retriever
gen_outputs = self.generator(
input_ids=context_input_ids,
attention_mask=context_attention_mask,
encoder_outputs=encoder_outputs,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
return_dict=True,
)
...First, notice how we can train either both the generator and the retriever or the generator only. In case of the former, the retrieved_doc_embeds will be recalculated using the RagModel’s own ctx_encoder for retrieved documents, instead of using the encoded results directly from RagRetriever, therefore allowing backpropagation to happen on retriever embedding. Second, notice how the generator assumes an encoder-decoder architecture (BART, T5, etc.) and requires decoder_input_ids. Actually, anything apart from input_ids are optional. The decoder_input_ids will be the decoder’s own generation during inference, and is usually the target labels shifted to the right during training.
Let’s examine more closely the retrieval process. Typically, the retriever is a class of type RagRetriever with the following key codes:
class RagRetriever:
...
def __call__(
self,
question_input_ids: List[List[int]],
question_hidden_states: np.ndarray,
prefix=None,
n_docs=None,
return_tensors=None,
) -> BatchEncoding:
...
# key retrieval code, self.retrieve uses the index's get_top_docs() method, where its actual implementation depends on how you indexed your documents.
# For HFIndexBase, it utilizes datasets.Dataset.search_batch() to find the nearest document ids to the query.
retrieved_doc_embeds, doc_ids, docs = self.retrieve(question_hidden_states, n_docs)
input_strings = self.question_encoder_tokenizer.batch_decode(question_input_ids, skip_special_tokens=True)
# this step appends the query to the retrieved documents
context_input_ids, context_attention_mask = self.postprocess_docs(
docs, input_strings, prefix, n_docs, return_tensors=return_tensors
)
...
return BatchEncoding(
{
"context_input_ids": context_input_ids,
"context_attention_mask": context_attention_mask,
...
},
tensor_type=return_tensors,
)
...
def postprocess_docs(self, docs, input_strings, prefix, n_docs, return_tensors=None):
...
# this is the key code to concatenate the retrieved document and the query. As shown here, they only used some separation tokens.
def cat_input_and_doc(doc_title, doc_text, input_string, prefix):
...
if doc_title.startswith('"'):
doc_title = doc_title[1:]
if doc_title.endswith('"'):
doc_title = doc_title[:-1]
if prefix is None:
prefix = ""
out = (prefix + doc_title + self.config.title_sep + doc_text + self.config.doc_sep + input_string).replace(
" ", " "
)
return out
...
...Finally, let’s take a look at how the marginalization is done in RAG. First, let’s take a look at RagSequenceForGeneration, where the forward method generates a response for all the retrieved documents. The marginalization here happens during loss calculation:
class RagSequenceForGeneration(RagPretrainedModel):
def forward(...):
outputs = self.rag(...)
loss = None
if labels is not None:
loss = self.get_nll(
outputs.logits,
outputs.doc_scores,
decoder_input_ids,
...
n_docs=n_docs,
)
def get_nll(self, seq_logits, doc_scores, target, ...):
...
# seq_logits dim = (batch*n_docs, tgt_len , #vocabs)
seq_logprobs = nn.functional.log_softmax(seq_logits, dim=-1).view(
seq_logits.shape[0] // n_docs, n_docs, -1, seq_logits.size(-1)
) # batch_size x n_docs x tgt_len x #vocab_size
doc_logprobs = nn.functional.log_softmax(doc_scores, dim=1).unsqueeze(-1).unsqueeze(-1)
# RAG-sequence marginalization
first_token_scores = seq_logprobs[:, :, :1, :]
second_token_scores = seq_logprobs[:, :, 1:2, :]
remainder = seq_logprobs[:, :, 2:, :]
rag_logprobs = torch.cat([first_token_scores, second_token_scores + doc_logprobs, remainder], dim=2)
# calculate loss
target = target.unsqueeze(1).unsqueeze(-1).repeat(1, n_docs, 1, 1)
assert target.dim() == rag_logprobs.dim()
ll = rag_logprobs.gather(dim=-1, index=target)
smooth_obj = rag_logprobs.sum(dim=-1, keepdim=True) # total sum of all (normalised) logits
ll, smooth_obj = _mask_pads(ll, smooth_obj)
# sum over tokens, exclude bos while scoring
ll = ll[:, :, 1:].sum(2) if exclude_bos_score and use_bos else ll.sum(2)
smooth_obj = smooth_obj.sum(2)
ll = ll.logsumexp(1) # logsumexp over docs
smooth_obj = smooth_obj.logsumexp(1)
nll_loss = -ll
...Notice how the marginalization at the token generation level stays the same in each forward (and consequently get_nll()) call by adding the document relevance (doc_logprobs) to the first real generated token (second_token_scores) after BOS (begin of sentence). Then marginalization happens again at ll = ll.logsumexp(1) #logsumexp over docs when calculating losses per batch. A related discussion can be found here. For RagTokenForGeneration, we have:
class RagTokenForGeneration(RagPreTrainedModel):
...
# key function used both in forward() and get_nll()
def marginalize(self, seq_logits, doc_scores, n_docs=None):
n_docs = n_docs if n_docs is not None else self.config.n_docs
# RAG-token marginalization
seq_logprobs = nn.functional.log_softmax(seq_logits, dim=-1).view(
seq_logits.shape[0] // n_docs, n_docs, -1, seq_logits.size(-1)
)
doc_logprobs = torch.log_softmax(doc_scores, dim=1)
log_prob_sum = seq_logprobs + doc_logprobs.unsqueeze(-1).unsqueeze(-1)
return torch.logsumexp(log_prob_sum, dim=1)
...
def forward(...):
...
outputs = self.rag(...)
loss = None
logits = outputs.logits
if labels is not None:
assert decoder_input_ids is not None
loss = self.get_nll(
outputs.logits,
outputs.doc_scores,
labels,
reduce_loss=reduce_loss,
epsilon=self.config.label_smoothing,
n_docs=n_docs,
)
# this is specific to RagTokenForGeneration, as it marginalizes at each step
if do_marginalize:
logits = self.marginalize(logits, outputs.doc_scores, n_docs)
...
...
def get_nll(self, seq_logits, doc_scores, target, reduce_loss=False, epsilon=0.0, n_docs=None):
...
# this is specific to RagtokenForGeneration, and is the same process as in forward
rag_logprobs = self.marginalize(seq_logits, doc_scores, n_docs)
target = target.unsqueeze(-1)
assert target.dim() == rag_logprobs.dim()
ll = rag_logprobs.gather(dim=-1, index=target)
smooth_obj = rag_logprobs.sum(dim=-1, keepdim=True) # total sum of all (normalised) logits
ll, smooth_obj = _mask_pads(ll, smooth_obj)
ll = ll.sum(1) # sum over tokens
smooth_obj = smooth_obj.sum(1)
nll_loss = -ll
...Notice how the function marginalize() is present during forward() call, as opposed to RAG-sequence generation where it is absent. This is consistent with the fact that in RAG-token generation, the retrieved documents’ relevance plays a role in determining next token probability. Also notice how in get_nll(), marginalize() does not only add the document relevance (doc_scores) to the token after BOS, but to all the tokens of the generation, again consistent with RAG-token generation’s idea that each token depends on document relevance.