MapReduce
What is MapReduce
MapReduce is a programming model originally proposed by Google in 2004 for processing large data sets. It allows parallel computation over a cluster of computers, while hiding the complexities of parallelization behind the scene. It is the basis of big data tools such as Apache Hadoop.
Model
A good way to define the model is to use a simple example of counting word occurrence in a bunch of documents. The following diagram depicts this process:
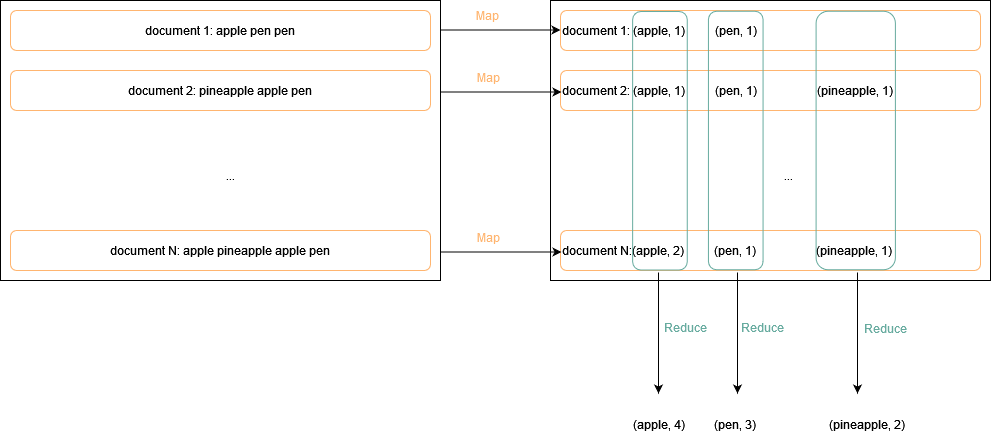
As shown above, the map operation consists of counting the word occurrences in each document, resulting in a set of intermediate key/value pairs, and the reduce operation consists of merging the intermediate pairs by key across the documents to get a global occurence count. The reason we do this is because both map and reduce operations only need a fraction of the documents in memory, and can thus be parallelized across different threads, processes or computer nodes. This parallelization can be hidden from the user of mapreduce, and the user only needs to define the map and the reduce functions as if they were on a single machine. In this example, the pseudocode of these functions are:
map(String doc):
for each word w in doc:
emitIntermediate(w, count(w)) // count(w) means number of w in doc
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int total_count = 0;
for each v in values:
total_count += v
emit(total_count)
More examples
The above model evidently does not limit to the word count example. In practice, many real applications can be abstracted using the mapreduce model, some examples include:
-
Count of URL access frequency: the map function processes logs of web page requests and outputs (URL, 1); the reduce function merges the map results by URL and emits (URL, total_count).
-
Inverted index: the map function parses each document and emits a sequence of (word, document ID) pairs; the reduce function accepts all map pairs, sorts the corresponding document IDs and emits (word, list(document ID)).
Parallelization
The implementation of parallelization is abstracted away from the map and reduce functions, and depends on the environment in which mapreduce is built. For large clusters of commodity PCs connected by networking, we have the following architecture:

As shown above, a user’s mapreduce program is first forked into different nodes, which are controlled by a master node whose role is to assign and track jobs on other worker nodes in a cluster. Out of the available idle nodes and according to configuration, some will be assigned the role of map, others the role of reduce. A shuffling process occurs in the middle to aggregate the results of all map nodes to the reduce nodes. This process can be break down more in detail as follow:

In the original paper, map nodes’ intermediate data pairs are written to their own local disk, and partitioned according to the hash number of the keys: $partition = hash(key)\ mod\ R$, where $R$ is the number of desired reduce outputs. Within a given partition, the intermediate key/value pairs are sorted in increasing key order, which facilitate key lookup. In some cases, a combiner function identical to the reduce function is applied on the map side to decrease the workload of the reduce nodes. This is only possible when the reduce function is commutative and associative, and this early partial merging can speed up certain classes of mapreduce operations.
Fault tolerance
In a large cluster of computer nodes, system failure is inevitable. The master node pings every worker periodically and if no response is received from a worker in a certain amount of time, it is marked as failed. Any inprogress or completed task on the failed node will be reset, and the node becomes idle again. The task is then re-executed on a different node. In the case of a rare master failure, the system will exit. The input data, which is typically organized by a shared file system (GFS in the original paper) is distributed in chunks of 64MB blocks across the different map workers. Typically, a worker’s input is stored locally and does not need bandwidth. However, 3 copies of each input are stored on different machines of the same network switch in case of system failure. In such case, a backup machine will re-execute the task associated with the input.
Modern extensions
Mapreduce is introduced in 2004, since then many systems have used and improved on this model, some result in much better performance. Apache Spark is a modern big data framework which improved upon mapreduce mainly on the following points: 1. it uses in-memory processing instead of disk I/O for intermediate data, 2. it uses a directed cyclic graph (DAG) to register different stages of data movement, which can be optimized as a whole by performing operations on the same data partition in a single stage and reduce data movement. Apache Flink is another popular modern framework with stream-processing capabilities as well as batch-processing capabilities.